In this article it is time to talk about how we secure our mobile application and our back-end API. Most of the information displayed in Fitradar mobile application is user dependent. Starting with user profile that has unique information for each user and can be changed or deleted only by the owner of the profile and ending with sport events map and timeline where information is built based on user preferences. And we have to provide access to third party integration services like Firebase Storage and payment gateway. As you can imagine in order to allow our application users to store and access personal information in a secure way we needed to implement user authentication and authorization.
It was clear from the very beginning that we are not going to develop our own authentication service but instead we will use third party solution. And before we started to explore available solutions we laid down following requirements:
- the access to Fitradar Web API should be granted only to authenticated users
- the access to Fitradar mobile application should be granted only to authenticated users
- the access to Fitradar Web API should have different privilege levels
- the access to third party resources like Firebase storage should be granted from the same authorization service
- the sign up and sign in pages should be part of the Fitradar app
After some investigation we came to conclusion that combination of OAuth2 and OpenID Connect protocols is the best solution for our needs since it:
- provide a mechanism for our resource and third party resource protection
- authenticate users using local or remote account store
Once we were clear about the authentication flow and protocols we started to look for the OAuth2 and OpenID Connect protocol implementation providers. First we wanted to have as much as possible control over authorization service, because we didn’t want to land in situation where authorization service would restrict our application look and functionality. For example RFC8252 (OAuth 2.0 for Native Apps) states that: “OAuth 2.0 authorization requests from native apps should only be made through external user-agents, primarily the user’s browser.” And that might enforce our app to use authorization server sign in and sign up user interface. And since on our back-end we are using ASP.NET Core we decided to use IdentityServer. For a while it worked quite well, but then we started to noticed that there are few aspects of the OAuth2 protocol that we have to implement by ourselves, like Access token lifetime in our mobile app. So we started to feel that we are spending too much time on implementing and maintaining the protocol features that we were quite sure should be working out of the box. Although IdentityServer offers full fledge OAuth 2.0 and OpenID Connect implementation but we still had to host it on our environment and maintain it by ourselves. And the maintenance question bothered us the most. For the startup company with limited human resources to have a solution that might require an administration seemed for us a high risk. If something goes wrong with authentication we will have to put all our effort to fix it, which means the other work will suffer from it. So we decided to look for a cloud solution that would free us from the maintenance burden. And once again we searched for available authentication and authorization providers but this time on a cloud. And after a while we came up with two potential providers: Firebase Authentication and Azure Active Directory. First Active Directory seemed a good solution for our needs:
- very well established user management system (although we just needed a tiny portion of all available feature)
- good documentation and code samples
- very easy integration with .Net Core
- possibility to use custom sign up and sign in pages
Although Azure AD integrated very well with our Web API and there are good sample projects how to use it with Android and iOS applications we were not sure how well it will integrate with Firabase Storage that we are using to store user images. It turns out we can grant the access to the Firebase storage resources only to Firabase users. To integrate with other OAuth providers Firabase creates a new user account after user has signed in for the first time and links it to the credentials. The fact that we would have user accounts on two authorization servers that we have control over really held us back from integrating Azure Active Directory B2C in our solution. From the other hand we were hesitant to start to use Firebase Authentication service in our ASP.NET Core solution as well, since we were not sure how much time and effort it will require from our team. But after all the Firebase Authentication is just another OAuth 2.0 and OpenID Connect provider that issues identity and access tokens and Jwt bearer authentication middleware in ASP.NET Core application can validate those tokens and authenticate a request. So we decided to spend some time to create a proof of concept project that would show us how much time we will have to invest in order to integrate Firebase Authentication in our Web API authentication solution. And it turns out that requires just a few lines of code in Startup.cs file:
services
.AddAuthentication(JwtBearerDefaults.AuthenticationScheme)
.AddJwtBearer(options => {
options.Authority = "https://securetoken.google.com/fitradar-firebase-project";
options.TokenValidationParameters = new TokenValidationParameters
{
ValidateIssuer = true,
ValidIssuer = "https://securetoken.google.com/fitradar-firebase-project",
ValidateAudience = true,
ValidAudience = "fitradar-firebase-project",
ValidateLifetime = true
};
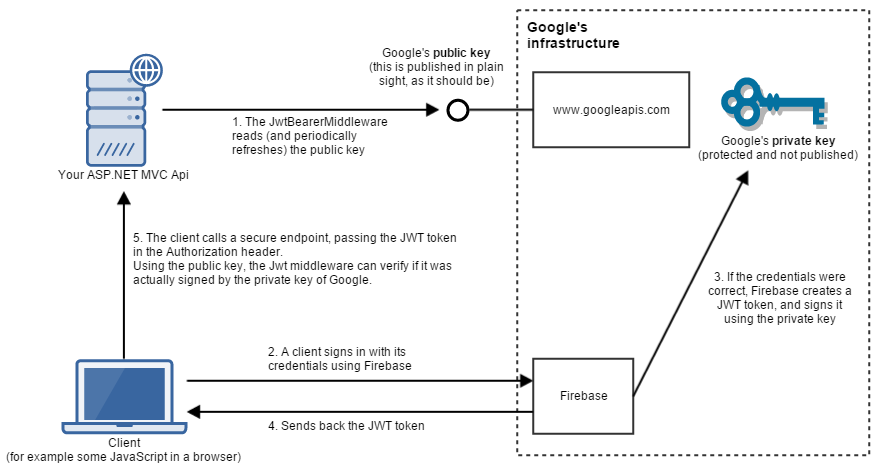
});And bellow is the final solution we are using to secure our and third party resources and authenticate a user
Please visit our website and join the mailing list. Our app is coming soon: