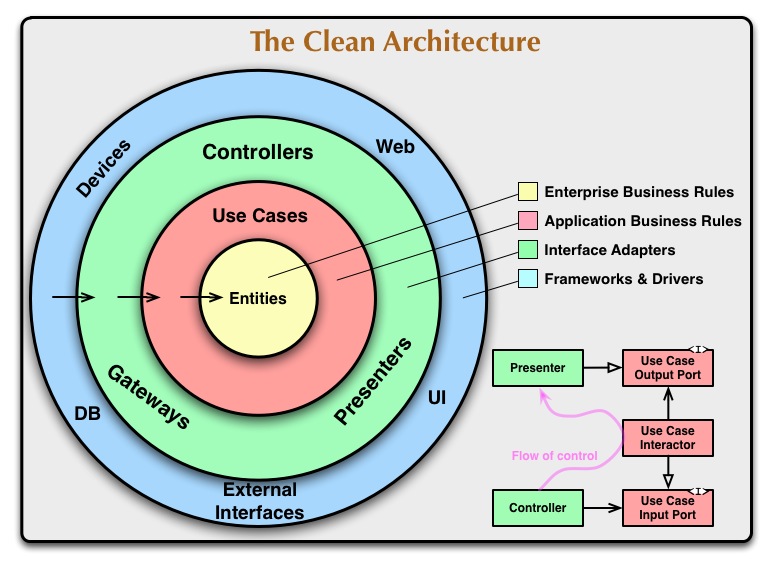
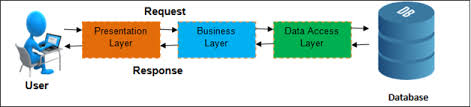
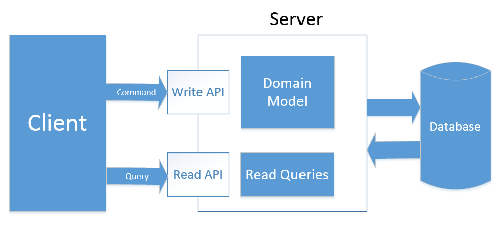
Recently our team finished the work on FitRadar booking system. That was quite a challenging task and I decided to share some insights and knowledge we gained during the design and development of this system. Already on the early stage of designing and requirement gathering it was clear that ticket booking system on the back-end should be independent from the rest of the Fitradar system because we wanted to introduce Event Sourcing for such entities as Order and Payment. Since these two entities are responsible of money charging and money is always a very sensitive topic, we wanted to make sure we can always track down the state changes in booking and payment processes. But to what degree it should be independent was the question we had to answer.
Let’s start with a simple case we considered – one process application. In this kind of applications all communications between objects occur within one process and it means all libraries needed for application are loaded in single process. Usually when we talk about the client side applications – Android, iOS or client side JavaScript, then most of the time these kind of applications work within one process and rarely leave the boundaries of that process set by OS. In such case the isolation can be introduced on the code level, like implementing the new feature in a new library, but at runtime we are somewhat limited. Since all objects share the same process:
- fault in one object might lead to crash in another object
- the load of a single object affects the whole process, so we can’t assign PC resources to separate app components. It means you can only scale the whole application, usually by creating a new instance of the application. This starts to play a big role when app is hosted on cloud environment like Azure, Google Cloud or AWS where we must pay for used resources.
- It is hard to apply new technology or framework to the new feature. Usually the whole application is build based on single architectural pattern like MVC and CRUD or MVC and CQRS and it is hard to introduce one more pattern (if we already using simple Data Access Objects for working with data coming from web, then it will take some time to introduce CQRS with Event Sourcing) in the same application. It is much simpler to create a new application.
So there is very little we can do about object decoupling at runtime in single process application case, but do we really need to deploy a booking system in a separate application? Maybe we can just isolate our booking system in a separate library and still run it in the same process with the rest of FitRadar libraries? And so we started to investigate it. Very quickly we noticed that our ideas of making booking system independent from the rest of application strongly reassembles the principles of Microservices architecture . And since now days there are a lot of talks around the Microservices we thought that our project might be a good candidate to move to Microservices architecture. But just because something is promoted doesn’t mean it fits your needs. You usually don’t start the development of application as a distributed system, unless it was a requirement from the beginning. Applications usually mature to the state when Monolithic Architecture doesn’t satisfy the initial requirements and a team starts to consider switching to Microservices Architecture. And we wanted to make sure that this is the time when the new feature requires us to switch to the new Architecture to make the development easier in the future. Here are the advantages of Microservices Architecture that really attracted our attention:
- it gives us a smaller code base to work with. It is a really huge benefit if you consider that at certain point a team more and more starts to think about how properly structure the project (how to write the Clean Code), that any new developer could easy understand it and navigate it. And putting a Booking system as a separate solution would allow as to reduce the code complexity and as result would allow developers navigate faster and add new code faster. If you have ever worked on enterprise scale application development then you know how much time it can take just to figure out where to put your new code.
- Web API end to end tests and Integration tests can run much faster because there is no need to load all of the Fitradar system libraries only those related to booking system. This advantage really starts to shine when we enter the test phase.
- It allows us to scale booking system and the rest of the back-end application independently. The booking system is more focused on data writing in the database on the other hand main back-end application is focused on data serving. We expect thousands of data requests a day while user will be navigating around in mobile application and just few bookings a day.
- Improved fault isolation
And for our project it seemed that we will gain more than loose if we will treat booking system as separate application and deploy it in a separate process. So we gave it a try.
Visit our website: http://fitradar.me/ and join the mailing list. Our app is coming soon!