In this article it’s time to talk about the way how we are testing our application and the strategy for testing we laid down in the application design phase. The experience in the past showed us that one of the good design outcomes is easy testable application. Therefore from the very beginning along with the application architecture we were designing our testing strategy.
The goal of the testing application is to achieve a flawless work of it. The simplest way how to test an application is to do a manual tests, but these tests definitely are not the most effective. Along with the software development evolution test approaches evolved as well. We already new and applied in our other projects such tests as unit tests, integration tests, functional tests and regression tests. But since in our team we don’t have a person who knows about testing techniques, can develop and design an application, we developers decided to explore different testing strategies together with QA who mostly does the tests manually. So we started to investigate other teams experience, information in books and on the web, and started to lay down foundation for our own test strategy that would fit our needs.
The thing we decided to start with was “Test pyramid” the term Mike Cohn came up with in his book Succeeding with Agile. The pyramid gave us some understanding how to start to organize the tests.
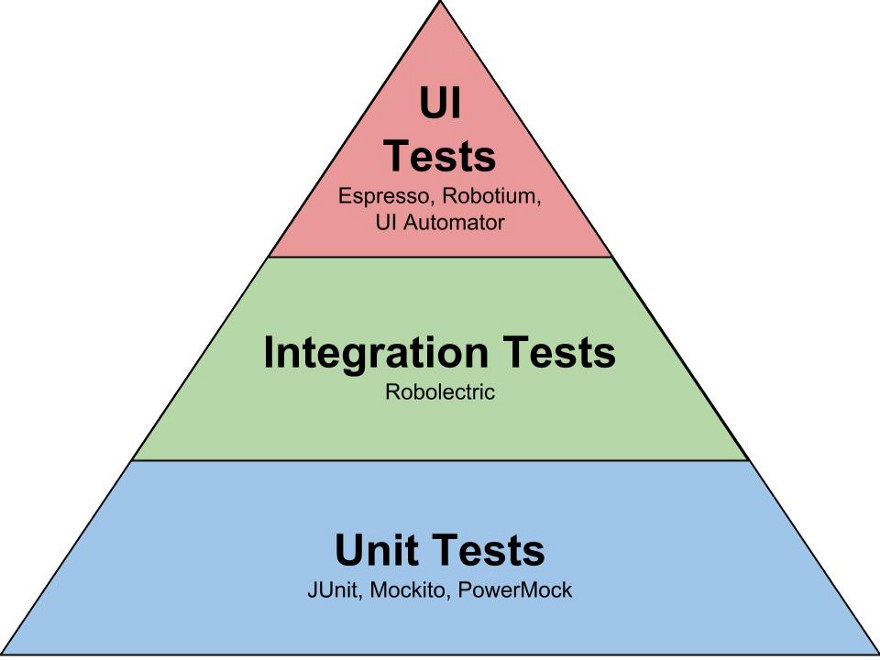
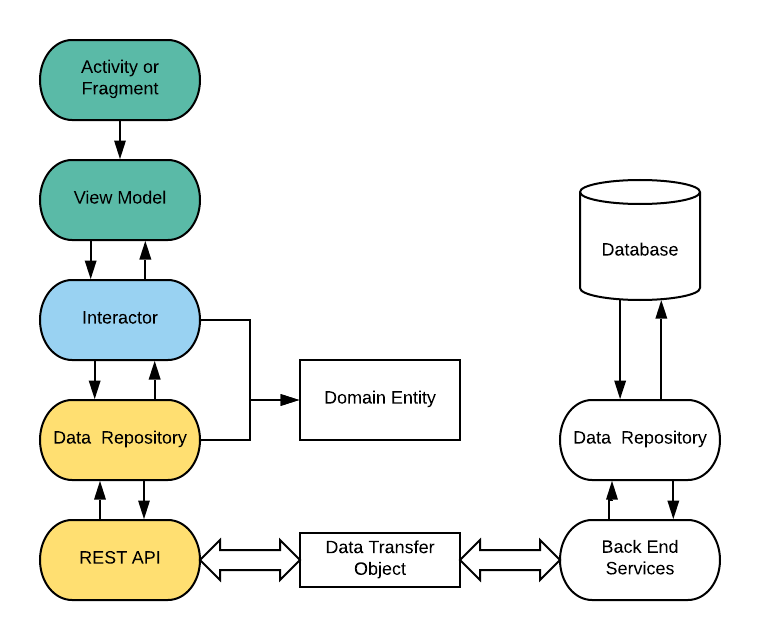
Unit Tests. Taking in to account our own experience, and the information we obtained it was clear that unit tests will be foundation for our test suite. To be able to easy and what is most important quickly write unit tests one should be able to isolate different peaces of software. In case of OOP the paradigm we are following we should be able easy isolate classes. In my opinion this is one of the core principles to successful unit tests. But in order to do that we must have a design that would allow us to isolate the classes. And that is why the dependency injection became very important technique in our software and I even dedicated the whole blog article to it. And to make it easier to implement this principle in our Android application we chose to use Dagger 2 framework. Once we wrote a use case implementation and accompanied unit tests we ask are our QA to test it. Very soon we discovered that despite the fact that we had a quite good coverage of code by unit tests QA still was finding bugs. And as you can guess the errors occurred in the code that interacted with framework, in our case Android framework. So now it became obvious we needed integration tests to make sure that our code callings to third party libraries or framework work flawless.
Integration Tests. According to Test pyramid these tests should be less than unit tests and indeed we already had tests that cover our own code logic, and so in these tests we decided to test only the connection points between our code and the third party libraries. For example in our application we are fetching data from the server and caching the data in database. In our Android application we are using Room persistence library. There is no really way how to test DAO interfaces, without performing the operations on database. And so we had to write tests that involve Room library. Another example is our code that interacts with our back end server via Retrofit library. And again we had to write tests that involve Retrofit library. Although these tests were written in the same manner as unit tests using Junit test framework they covered more than our class or method and were considered as a separate type of tests.
UI tests. The main reason why we decided to write UI tests is because we wanted to fully automate the test process and make it a part of Continues Integration (CI) process. So for Android we chose Espresso framework and as a firsts test we wrote navigation tests, that made sure that we can navigate to every page we have in our application. Then we wrote the tests only for the errors that QA reported and so comparing with the rest of the tests these are making only small portion of all tests.