In this article I wanted to share our team experience on how we arrived at particular architecture on our back-end solution. On the back-end we wanted to work with technologies that our team is familiar with and had an experience with before but at the same time is not outdated and has a great potential in the near future. In our case it was ASP.NET Core framework. I am not going in to the endless discussion about what framework or language is the best, from my point of view it is useless since such a topic is very biased. And I already mentioned in one of my previous blogs that despite the fact that the software development supposed to be an exact science, and many aspects of it really is, the choice of language, frameworks and best practices many times is just a matter of personal preference – something that you feel more comfortable with and it doesn’t have any scientific justification. And when I will be laying down the arguments for the solution we came up with it will be presented from our team’s point of view and how it helped us to make a design and implementation more clear and easier to understand, which might not be the case for other teams.
ASP.NET Core comes comes with some prepacked architecture that satisfied our needs. For REST full Web API solution MVC is very suitable design pattern and gave us a good starting point. Dependency injection in turn allowed us easy start to write unit tests and mock dependencies. But the more complex solution became the more we saw that we need to extend our initial project with more general architecture, after all MVC is just an UI level design pattern. This wasn’t the first project in our team’s experience when we had to split application’s code in layers. Some years ago very common was 3 tier architecture:
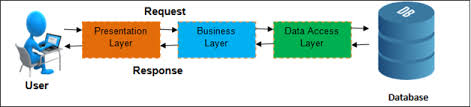
And we used this architecture quite a lot. In some projects we felt it suited our needs perfectly, but in some we had a feeling that we do some kind of workaround to fit the architecture. For some time I could not really even explain why those projects didn’t comply with the above architecture until the moment when I read about Command and Query Responsibility Segregation (CQRS) pattern. It was one of those aha moments when you discover what was really bothering you all this time. In the traditional 3 tier architecture the same data model and the same database is used for read and write operations. It works well when we need to display the same information we saved earlier. But the more complex application becomes the more a model we use to save data starts to deviate from a model we use to display data. For example most of the applications today require a user to create a profile or an account. Let’s say we save this information in table User and in order to do that we use an model with the same name. In case we want to see our account information we will fetch the data from the same table User. But this is only one use case where we are displaying the information about user. In real world applications information about user is displayed in many other pages together with other information, for example in e-store that would be information about product and product category, in blog that would be a post and so on. And in order to receive data suitable for a view complex queries with joins and sub-queries are used. And not only models for read and write operations are different but the requirements for those operations are different as well. In case of insert update and delete operations the database should be normalized that allows us to minimize duplicate data and avoid data modification issues. The database normalization usually results in more tables than initial design. The query operations on the other hand are focused more on performance, that can be improved by denormalizing tables. The beauty of CQRS is that it allows to separate the write and read flows by using different models and even different databases. In last case it would allow to scale the databases for read and write operations independently. And at some point of time this feature may become very crucial since write operations are significantly less that queries. As you can see there are several levels how far we can separate commands (insert, update, delete operations) from queries (read operations):
- The lowest level of read and write operation separation is on Repository level – we are using the same Domain model for write operations and for display data in UI, but we have a separate method in Repository for querying database. In order to display only necessary data we have to introduce View model and map data from Domain model to View model.
- Next level of CQRS maps View Models directly to database queries. There is no need for mapping between Domain model and View model anymore. On database level we still have normalized tables that correspond to Domain model. View models in this case correspond to queries that involves joins and sub queries.
- The two above levels of separation sometimes are not regarded as real CQRS pattern but are known as CQS (Command Query Separation) pattern, therefore only the next level of separation when write and read operations are regarded as two separate workflows throughout an application is considered as CQRS pattern.
- The final level of separation goes further even to the database layer, where each type of operations interact with its own database
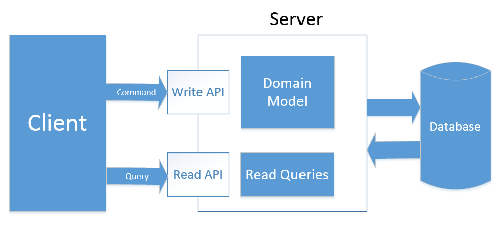
In our back end API solution we decided to separate write and read operation on the application level and not to use a separate storage, but instead we are using SQL Views for queries. It allows us avoid data synchronization between the databases. But at the same time architecture is opened for further extension and possibility to add separate storage for queries. And so we ended up with following architecture:
Visit our website and join the mailing list. Our app is coming soon: